
O Google tem aprimorado significativamente sua capacidade de lidar com JavaScript ao longo dos anos.
Originalmente, o Googlebot (o robô de rastreamento do Google) tinha dificuldade para processar páginas que dependiam de JavaScript, o que resultava em conteúdo não indexado.
No entanto, com a evolução da tecnologia de rastreamento, o Googlebot agora é capaz de renderizar e processar páginas baseadas em JavaScript de forma muito mais eficaz.
Mesmo assim, ainda existem desafios e práticas recomendadas que devem ser levadas em consideração para garantir a indexação adequada de páginas JavaScript.
Índice
Como o Google processa as páginas da web
O Googlebot processa páginas da Web em JavaScript em três fases: rastreamento, renderização e indexação.
Aqui está uma ilustração simples desse processo:
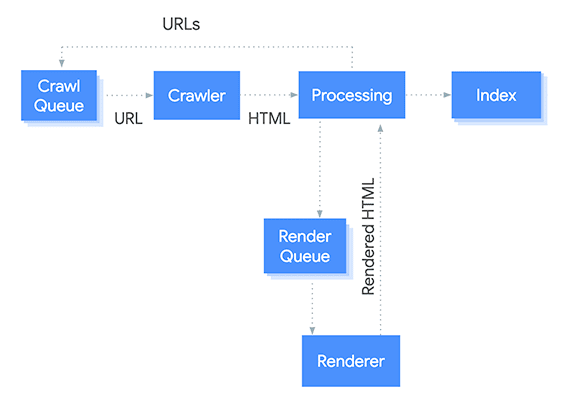
1 – Fila de rastreamento
O Googlebot, o rastreador, atualiza continuamente a lista de URLs a serem rastreadas com base em vários sinais, como mapas do site, links descobertos em outras páginas e alterações em páginas existentes.
2 – Rastreador
Quando o Googlebot solicita o HTML de uma página, ele também envia vários sinais para o servidor da web, como o agente do usuário (indicando que é um rastreador) e o idioma preferido para a resposta.
3 – Processamento
O HTML é analisado e analisado para extrair vários sinais, como links para outras páginas, dados estruturados (como marcação schema.org) e meta tags (como o título e descrição).
O Google também procura por práticas de spam ou manipulação, como texto ou links ocultos, enchimento de palavras-chave e ocultação.
Descoberta de URL
URLs encontrados na página são adicionados à Fila de Rastreamento, mas alguns podem ser filtrados com base em vários critérios, como conteúdo duplicado ou baixa qualidade.
Indexação
O Google verifica vários sinais para determinar se a página deve ser indexada (adicionada ao índice de pesquisa) ou não. Por exemplo, páginas com uma meta tag “noindex” ou no arquivo robots.txt são excluídas.
Páginas que já estão no índice também podem ser re-rastreadas para verificar atualizações, como novo conteúdo ou alterações no conteúdo existente.
Renderização
O Google verifica se a página requer renderização de JavaScript para ser exibida corretamente. Se sim, ele adiciona a URL à Fila de Renderização para ser renderizada pelo Serviço de Renderização da Web (WRS).
O Google também pode usar uma versão em cache da página para resultados de pesquisa até que a versão renderizada esteja disponível.
Canonização
O Google tenta identificar a versão canônica de uma página, que é a URL preferida a ser exibida nos resultados de pesquisa. Isso pode envolver olhar para o elemento de link rel = “canonical”, cadeias de redirecionamento e outros sinais.
4 – Fila de Renderização
URLs que requerem renderização de JavaScript são adicionadas à Fila de Renderização, que é processada pelo Serviço de Renderização da Web.
5 – Renderizador
O WRS renderiza a página usando um navegador sem cabeçalho (como o Chrome) e envia o HTML renderizado de volta para processamento adicional.
6 – Índice
O HTML renderizado é analisado e analisado para extrair sinais adicionais, como conteúdo que foi gerado dinamicamente pelo JavaScript. O Google também verifica dados estruturados e links e calcula vários sinais, como PageRank (que mede a importância de uma página com base no número e qualidade de links para ela).
7 – Classificação (ranking)
O algoritmo de classificação do Google usa o índice para fornecer resultados de pesquisa relevantes para cada consulta. O algoritmo leva em consideração vários sinais, como a relevância e qualidade do conteúdo.
Para que o Google entenda uma página que depende fortemente de JavaScript, é necessário que ele passe pela fase completa de renderização, em vez de poder acessá-la diretamente.
Como o Google lida com JavaScript atualmente
Renderização em Dois Estágios
O Google usa um processo de renderização em duas etapas para processar páginas que utilizam JavaScript:
- Crawling Inicial (HTML estático): Quando o Googlebot rastreia uma página pela primeira vez, ele tenta coletar o HTML básico da página. Nesse estágio, o Googlebot pode não executar o JavaScript completamente. Se o conteúdo principal da página estiver embutido em JavaScript que precisa ser executado, ele pode não ser visto neste primeiro estágio. Isso significa que apenas o HTML estático ou o conteúdo carregado diretamente no HTML será acessado de imediato.
- Renderização Completa (HTML dinâmico): Após a coleta inicial, o Googlebot coloca a página em uma fila de renderização. Nesta segunda etapa, o Googlebot executa o JavaScript presente na página para obter o conteúdo dinâmico. Esse processo é realizado em uma infraestrutura baseada no Chrome headless, que é uma versão sem interface gráfica do navegador Google Chrome.
Essa abordagem em dois estágios ajuda a lidar com o conteúdo dinâmico de páginas JavaScript, mas introduz um atraso na indexação completa do conteúdo que depende de scripts.
Execução de JavaScript no Googlebot
Atualmente, o Googlebot utiliza o Chrome 110 (versão atualizada do Google Chrome) como seu mecanismo de renderização. Isso significa que o Googlebot pode lidar com praticamente qualquer funcionalidade JavaScript moderna que um navegador comum pode processar.
Ele executa o JavaScript e atualiza o Document Object Model (DOM) da página, permitindo que o conteúdo gerado dinamicamente seja indexado.
No entanto, é importante notar que a execução de JavaScript pode ser mais lenta e consumir mais recursos do que o rastreamento de HTML estático. Dependendo da complexidade da página e da quantidade de JavaScript, o Googlebot pode demorar mais tempo para renderizar e indexar uma página.
Recursos Carregados Tarde ou Bloqueados
Se o conteúdo de uma página depende de recursos que não podem ser carregados ou que demoram muito para serem executados, isso pode afetar a capacidade do Googlebot de processar e indexar a página. Por exemplo:
- Arquivos JavaScript Bloqueados: Se o arquivo JavaScript essencial estiver bloqueado pelo arquivo
robots.txt, o Googlebot não poderá executá-lo, o que pode resultar em conteúdo ausente na renderização. Portanto, é fundamental garantir que os arquivos CSS e JavaScript essenciais não estejam bloqueados norobots.txt. - Recursos de Terceiros: Se a página depende de bibliotecas externas ou de APIs de terceiros, o Googlebot pode não conseguir acessá-las, especialmente se houver problemas de tempo de resposta ou restrições de acesso. Isso pode causar falhas na renderização e conteúdo não indexado.
- Conteúdo Carregado Assíncrona ou Tardiamente: Elementos de JavaScript que usam técnicas como
lazy loadingouAJAXpara carregar conteúdo após o carregamento inicial da página podem não ser renderizados a tempo pelo Googlebot. Isso pode resultar na ausência desse conteúdo na versão indexada da página.
Limitações de Renderização
Embora o Google tenha melhorado significativamente na execução de JavaScript, ainda existem algumas limitações que afetam o desempenho do rastreamento e a indexação:
- Orçamento de Rastreamento (Crawl Budget): Como o Google tem um número limitado de recursos para rastrear e renderizar páginas, sites maiores ou mais complexos que dependem fortemente de JavaScript podem consumir mais orçamento de rastreamento, o que pode atrasar a indexação de outras páginas do site.
- Recursos Pesados e Lentos: Páginas com grandes quantidades de JavaScript, ou que fazem muitas requisições de rede, podem ser lentas para renderizar e, como resultado, podem ter problemas de indexação. O Google dá preferência a páginas que carregam rapidamente e são facilmente rastreadas.
Melhores Práticas para SEO em Páginas JavaScript
Para garantir que páginas baseadas em JavaScript sejam bem rastreadas e indexadas, os desenvolvedores e SEOs devem seguir algumas práticas recomendadas:
- Pré-renderização: Para páginas que utilizam muito JavaScript, uma estratégia eficaz é a pré-renderização, onde o conteúdo é gerado como HTML estático no servidor e entregue ao Googlebot. Ferramentas como Prerender.io e frameworks como Next.js facilitam a implementação dessa técnica.
- Server-Side Rendering (SSR): Com a renderização do lado do servidor, o HTML completo é entregue ao Googlebot (e aos navegadores), o que garante que o conteúdo seja indexado rapidamente e de forma eficiente. Frameworks como Nuxt.js (para Vue) e Next.js (para React) facilitam a implementação do SSR.
- Hydration: Em algumas aplicações, a renderização do lado do servidor é combinada com JavaScript no lado do cliente. O conteúdo é entregue inicialmente pelo servidor e depois “hidratado” pelo JavaScript no lado do cliente para adicionar interatividade. Isso garante que o conteúdo seja indexado e que a página permaneça interativa para o usuário.
- Testar a Renderização com o Google Search Console: A ferramenta de Inspeção de URL permite que você veja como o Googlebot renderiza uma página. Isso é essencial para identificar qualquer problema de renderização ou conteúdo ausente causado por JavaScript.
- Uso de
noscript: Para garantir que algum conteúdo seja sempre visível para o Googlebot (caso haja problemas na execução do JavaScript), você pode utilizar a tag<noscript>para fornecer uma versão básica do conteúdo.
Ferramentas de Diagnóstico de SEO para JavaScript
Existem várias ferramentas que ajudam a entender como o Google processa JavaScript em suas páginas:
- Google Search Console: A ferramenta de inspeção de URLs permite visualizar como o Google vê e renderiza sua página.
- Lighthouse: Uma ferramenta automatizada que ajuda a auditar a performance, acessibilidade e SEO de uma página, incluindo a performance de JavaScript.
- Rendertron: Uma ferramenta que simula a renderização de páginas em JavaScript e ajuda a visualizar o conteúdo que será rastreado.
- Web Vitals: Monitorar métricas de desempenho como Largest Contentful Paint (LCP), First Input Delay (FID) e Cumulative Layout Shift (CLS) é crucial para entender a experiência de renderização.
JavaScript e os problemas de SEO
Simplificando, o Google não pode indexar o conteúdo até que o JavaScript tenha sido renderizado – esse processo poderá ser bastante complicado especialmente em sites parrudos, já que será preciso realizar uma dupla verificação e renderizar todas as páginas do site.
Isso poderá afetar negativamente o desempenho de SEO.
Embora o atraso entre o rastreamento e a renderização tenha diminuído com as melhorias recentes no Googlebot, não há garantia de que o Google executará o código JavaScript em espera em sua fila WRS, por motivos como:
- Bloqueado em robots.txt
- Tempo limite
- Erros
Assim, o JavaScript causa problemas de SEO quando o conteúdo principal depende dele, mas não é renderizado pelo Google.
A renderização de JavaScript é muito mais pesada em recursos para o Google do que apenas analisar HTML.
Ao usar JavaScript no site, é importante se certificar de que o conteúdo, imagens e links sejam exibidos mesmo com o JavaScript desativado.
Publicado originalmente em 12/08/2023 | Última atualização em 16/10/2024